Cohere Releases Tiny Aya: A 3B-Parameter Small Language Model that Supports 70 Languages and Runs Locally Even on a Phone
[ad_1]
Cohere AI Labs has released Tiny Aya, a family of small language models (SLMs) that redefines multilingual performance. While many models scale by increasing parameters, Tiny Aya uses a 3.35B-parameter architecture to deliver state-of-the-art translation and generation across 70 languages.
The release includes 5 models: Tiny Aya Base (pretrained), Tiny Aya Global (balanced instruction-tuned), and three region-specific variants—Earth (Africa/West Asia), Fire (South Asia), and Water (Asia-Pacific/Europe).
The Architecture
Tiny Aya is built on a dense decoder-only Transformer architecture. Key specs include:
- Parameters: 3.35B total (2.8B non-embedding)
- Layers: 36
- Vocabulary: 262k tokenizer designed for equitable language representation.
- Attention: Interleaved sliding window and full attention (3:1 ratio) with Grouped Query Attention (GQA).
- Context: 8192 tokens for input and output.
The model was pretrained on 6T tokens using a Warmup-Stable-Decay (WSD) schedule. To maintain stability, the team used SwiGLU activations and removed all biases from dense layers.
Advanced Post-training: FUSION and SimMerge
To bridge the gap in low-resource languages, Cohere used a synthetic data pipeline.
Performance Benchmarks
Tiny Aya Global consistently beats larger or same-scale competitors in multilingual tasks:
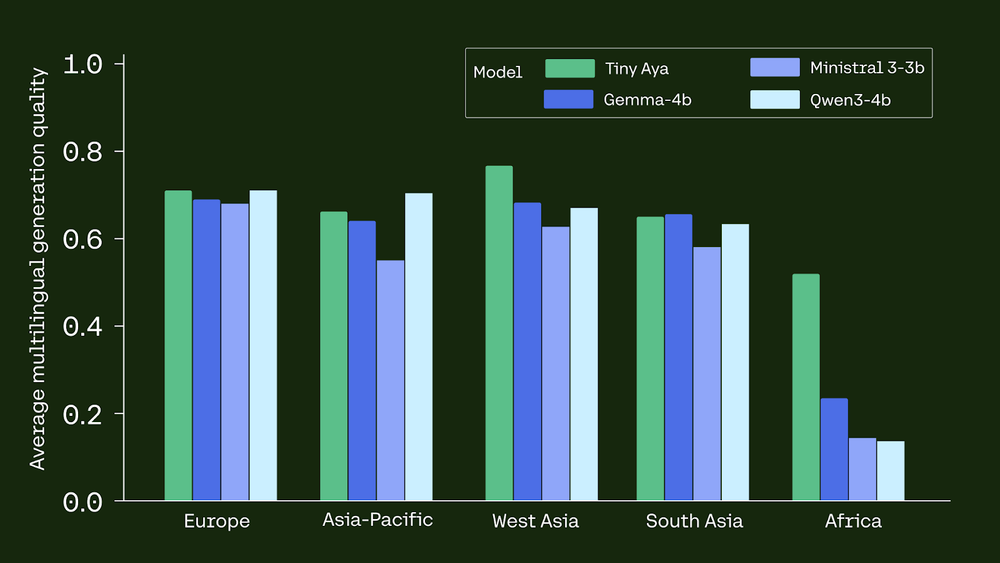
- Translation: It outperforms GEMMA3-4B in 46 of 61 languages on WMT24++.
- Reasoning: In the GlobalMGSM (math) benchmark for African languages, Tiny Aya achieved 39.2% accuracy, dwarfing GEMMA3-4B (17.6%) and QWEN3-4B (6.25%).
- Safety: It holds the highest mean safe response rate (91.1%) on MultiJail.
- Language Integrity: The model achieves 94% language accuracy, meaning it rarely switches to English when asked to reply in another language.
On-Device Deployment
Tiny Aya is optimized for edge computing. Using 4-bit quantization (Q4_K_M), the model fits in a 2.14 GB memory footprint.
- iPhone 13: 10 tokens/s.
- iPhone 17 Pro: 32 tokens/s.
This quantization scheme results in a minimal 1.4-point drop in generation quality, making it a viable solution for offline, private, and localized AI applications.
Key Takeaways
- Efficient Multilingual Power: Tiny Aya is a 3.35B-parameter model family that delivers state-of-the-art translation and high-quality generation across 70 languages. It proves that massive scale is not required for strong multilingual performance if models are designed with intentional data curation.
- Innovative Training Pipeline: The models were developed using a novel strategy involving Fusion-of-N (FUSION), where a ‘team of teachers’ (like Command A and DeepSeek-V3) generated synthetic data. A judge model then aggregated the strongest components to ensure high-quality training signals even for low-resource languages.
- Regional Specialization via Merging: Cohere released specialized variants—Tiny Aya Earth, Fire, and Water—which are tuned for specific regions like Africa, South Asia, and the Asia-Pacific. These were created by merging regional fine-tuned models with a global model using SimMerge to preserve safety while boosting local language performance.
- Superior Benchmark Performance: Tiny Aya Global outperforms competitors like Gemma3-4B in translation quality for 46 of 61 languages on WMT24++. It also significantly reduces disparities in mathematical reasoning for African languages, achieving 39.2% accuracy compared to Gemma3-4B’s 17.6%.
- Optimized for On-Device Deployment: The model is highly portable and runs efficiently on edge devices; it achieves ~10 tokens/s on an iPhone 13 and 32 tokens/s on an iPhone 17 Pro using Q4_K_M quantization. This 4-bit quantization format maintains high quality with only a minimal 1.4-point degradation.
Check out the Technical details, Paper, Model Weights and Playground. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

[ad_2]
Source link